Praxisleitfaden zur Auswertung von Umfragen

Die Auswertung einer Umfrage ist der Moment der Wahrheit. Hier verwandeln sich rohe Daten in handfeste Erkenntnisse, die am Ende des Tages strategische Entscheidungen untermauern. Es geht darum, in den Antworten systematisch zu graben, um Muster, Trends und statistisch belastbare Zusammenhänge freizulegen.
Erst die Pflicht, dann die Kür: Die Basis für valide Ergebnisse legen
Schon mal einen frischen Datensatz geöffnet und gedacht: "Und jetzt?" Keine Sorge, das kennt jeder. Viele springen direkt zu den statistischen Tests und klicken sich durch ihre Software. Die Realität sieht aber anders aus: Die wirklich entscheidende Arbeit – die sorgfältige Vorbereitung der Daten – kann gut und gerne bis zu 70 % der gesamten Analysezeit fressen. Ohne eine blitzsaubere, logisch strukturierte Datenbasis sind selbst die ausgeklügeltsten Verfahren am Ende wertlos.
Eine strategische Planung, bevor überhaupt die erste Analyse läuft, bewahrt einen davor, später in einer Sackgasse zu landen. Es geht nicht nur darum, ein paar Fehler zu korrigieren. Es geht darum, die Integrität der gesamten Studie zu sichern. Diese oft unsichtbare Vorarbeit entscheidet über die Validität und Zuverlässigkeit der Ergebnisse.
Warum die Vorbereitung das A und O ist
Stellen Sie es sich wie den Bau eines Hauses vor. Die Datenaufbereitung ist das Fundament. Wenn dieses Fundament schief oder brüchig ist, bekommt das ganze Gebäude – also Ihre Analyse und Ihre Schlussfolgerungen – früher oder später Risse. Im schlimmsten Fall stürzt es komplett ein. Ein schlecht vorbereiteter Datensatz führt fast zwangsläufig zu falschen Interpretationen und damit zu teuren Fehlentscheidungen.
In der Praxis heißt das konkret:
- Datenqualität sicherstellen: Inkonsistente Antworten, offensichtlicher Unsinn (wie ein Alter von 150 Jahren) oder doppelte Datensätze verzerren das Gesamtbild. Die müssen raus.
- Struktur schaffen: Offene Textantworten sind für sich genommen wertvoll, aber für statistische Analysen unbrauchbar. Sie müssen sinnvoll in quantitative Kategorien überführt, also kodiert werden.
- Vergleichbarkeit herstellen: Alle Variablen müssen korrekt formatiert und Skalen einheitlich definiert sein. Nur so sind Vergleiche zwischen verschiedenen Gruppen überhaupt statthaft.
Ein erfahrener Analyst verbringt die meiste Zeit nicht damit, Tests durchlaufen zu lassen. Er stellt sicher, dass die Daten, die in diese Tests einfließen, absolut wasserdicht sind. Jede Minute, die Sie in die Aufbereitung investieren, erspart Ihnen später Stunden an Frust, Korrekturschleifen und nagenden Zweifeln an den eigenen Ergebnissen.
Die Denkweise eines Analysten
Ein Profi startet die Auswertung einer Umfrage nie mit der Analyse selbst, sondern mit einer klaren Fragestellung, die den Weg vorgibt. Diese Denkweise hilft, die typischen Fallstricke von Anfang an zu umgehen. Bevor Sie auch nur einen einzigen Mittelwert berechnen, sollten Sie sich über die Gütekriterien Ihrer Forschung im Klaren sein. Eine gute Grundlage dafür bietet unser Artikel, der die wichtigsten Gütekriterien in der quantitativen Forschung verständlich erklärt.
Diese strategische Herangehensweise stellt sicher, dass Ihre Analyse nicht nur technisch sauber ist, sondern auch die Forschungsfragen beantwortet, die Sie sich am Anfang gestellt haben. Das ist der entscheidende Schritt vom reinen Datensammler zum echten Erkenntnisgewinner. Und dieser erste Schritt legt das Fundament für alles, was danach kommt.
Rohdaten in eine verlässliche Analysebasis umwandeln
Der Moment ist da: Der Datensatz aus Ihrer Umfrage ist exportiert. Die Neugier ist groß, endlich in die Zahlen einzutauchen und die ersten Erkenntnisse zu gewinnen. Doch bevor Sie sich auf die Suche nach Mustern machen, kommt ein entscheidender, oft unterschätzter Schritt: die Datenbereinigung, auch als Data Cleaning bekannt.
Dieser Prozess verwandelt einen potenziell chaotischen, fehleranfälligen Rohdatensatz in eine saubere, verlässliche Analysebasis. Man kann es nicht oft genug betonen: Das ist das Fundament für jede valide Auswertung. Ohne diesen Schritt bauen Sie Ihre Schlussfolgerungen auf Sand. Stellen Sie sich vor, Sie übersehen, dass ein paar unzufriedene Kunden die Umfrage versehentlich doppelt ausgefüllt haben. Sofort wäre Ihre Analyse zur Kundenzufriedenheit verzerrt und könnte Sie zu völlig falschen Geschäftsentscheidungen verleiten. Datenaufbereitung ist also keine lästige Pflicht, sondern eine strategische Notwendigkeit.
Die folgende Grafik bringt es auf den Punkt und zeigt den grundlegenden Ablauf, bevor die eigentliche statistische Analyse überhaupt beginnt.
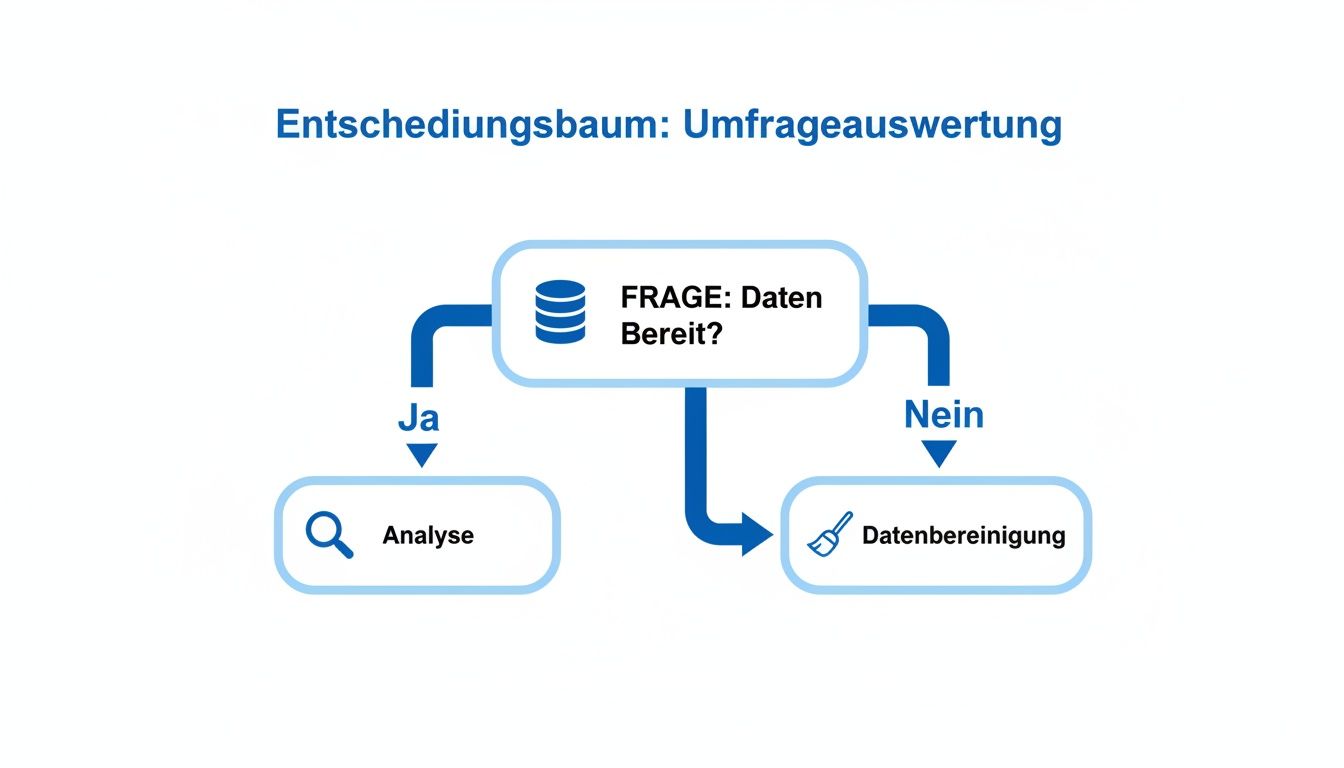
Die Grafik macht klar: Der Weg zur Analyse führt immer über eine sorgfältige Prüfung und Bereinigung, falls die Daten nicht schon in einem perfekten Zustand vorliegen – was in der Praxis so gut wie nie der Fall ist.
Systematische Fehlersuche im Datensatz
Der erste Durchgang durch die Daten gleicht Detektivarbeit. Sie jagen nach allem, was unplausibel, inkonsistent oder schlichtweg falsch aussieht. Ein systematischer Ansatz ist hier Gold wert.
Starten Sie mit einer einfachen Plausibilitätsprüfung für jede einzelne Variable. Hat ein Teilnehmer ein Alter von „999“ angegeben? Solche Werte sind oft Platzhalter für verweigerte Antworten und müssen korrekt als fehlend kodiert werden. Genauso wichtig: Kontrollieren Sie kategoriale Variablen. Gibt es bei „Geschlecht“ vielleicht Tippfehler wie „weiblich“ und „weibich“? Solche Kleinigkeiten müssen vereinheitlicht werden, sonst werden sie als separate Kategorien gezählt.
Hier sind ein paar typische Fehlerquellen, die Sie auf dem Schirm haben sollten:
- Unrealistische Werte: Suchen Sie nach Werten, die außerhalb des logisch möglichen Bereichs liegen. Ein Klassiker ist eine Bewertung von 6 auf einer Skala von 1 bis 5.
- Doppelte Einträge: Prüfen Sie, ob einzelne Personen die Umfrage mehrfach ausgefüllt haben. Das kann die Ergebnisse massiv verfälschen.
- Antwortmuster: Halten Sie Ausschau nach Teilnehmern, die stur die gleiche Antwortoption wählen (Straight-Lining). Das deutet oft auf mangelnde Aufmerksamkeit hin und kann ein Grund sein, den Fall auszuschließen.
Offene Nennungen in quantitative Daten überführen
Freitextantworten sind oft eine Goldgrube für qualitative Einblicke. Um sie aber statistisch auswerten zu können, müssen wir sie quantifizieren. Dieser Prozess nennt sich Kodierung.
Nehmen wir an, Sie fragen nach dem Hauptgrund für die Nutzung eines Produkts und erhalten Hunderte individuelle Antworten. Ihre Aufgabe ist es jetzt, aus diesem Wust ein logisches Kategoriensystem zu entwickeln. Antworten wie „einfache Bedienung“, „intuitives Design“ und „schnell gelernt“ könnten Sie beispielsweise in der übergeordneten Kategorie „Benutzerfreundlichkeit“ bündeln.
Praxistipp: Entwickeln Sie Ihr Kategoriensystem nicht im stillen Kämmerlein. Lassen Sie einen Kollegen unabhängig von Ihnen dieselben Daten kodieren. Ein anschließender Vergleich der Ergebnisse (die sogenannte Intercoder-Reliabilität) ist ein fantastischer Weg, um die Objektivität und Klarheit Ihres Systems zu prüfen und zu schärfen.
Der strategische Umgang mit fehlenden Werten
Kaum eine Umfrage kommt ohne sie aus: fehlende Werte, auch „Missing Values“ genannt. Teilnehmer überspringen Fragen oder brechen einfach ab. Wie Sie damit umgehen, kann Ihre gesamte Analyse beeinflussen. Die Holzhammermethode – einfach alle Fälle mit fehlenden Werten löschen (Listwise Deletion) – kann die Stichprobengröße drastisch reduzieren und die Ergebnisse verzerren, vor allem dann, wenn die fehlenden Werte nicht zufällig verteilt sind.
Glücklicherweise gibt es verschiedene Strategien, die je nach Situation mehr oder weniger sinnvoll sind.
Die folgende Tabelle gibt einen Überblick über die gängigsten Verfahren und ihre Tücken in der Praxis.
Umgang mit fehlenden Werten in der Praxis
Ein Vergleich gängiger Verfahren zur Behandlung von fehlenden Datenpunkten, inklusive ihrer praktischen Vor- und Nachteile.
| Methode | Beschreibung | Vorteil | Nachteil |
|---|---|---|---|
| Listwise Deletion | Fälle mit mindestens einem fehlenden Wert werden komplett entfernt. | Sehr einfach umzusetzen; in SPSS oft die Standardeinstellung. | Kann Stichprobe stark reduzieren und zu signifikanten Verzerrungen führen. |
| Pairwise Deletion | Ein Fall wird nur für die spezifische Analyse ausgeschlossen, in der die Variable fehlt. | Erhält mehr Datenpunkte als die Listwise-Methode. | Die Analysen basieren auf unterschiedlichen Stichprobengrößen, was die Interpretation erschwert. |
| Mittelwert-Imputation | Fehlende Werte werden durch den Mittelwert der jeweiligen Variable ersetzt. | Erhält die volle Stichprobengröße und ist einfach in der Anwendung. | Reduziert die Varianz künstlich und kann Korrelationen verzerren. Mit Vorsicht zu genießen. |
| Multiple Imputation | Fehlende Werte werden mehrfach durch statistisch plausible Schätzungen ersetzt und die Analysen anschließend zusammengeführt. | Gilt als das statistisch robusteste Verfahren, um Verzerrungen zu minimieren. | Deutlich komplexer in der Anwendung und Interpretation. Eher für fortgeschrittene Nutzer. |
Die Wahl der richtigen Methode hängt stark von der Menge und dem Muster der fehlenden Daten ab. Gerade für wissenschaftliche Arbeiten ist eine sorgfältige Abwägung und eine klare Begründung der gewählten Strategie unerlässlich.
Ist das alles erledigt, liegt Ihnen endlich eine saubere Datenmatrix vor – der verlässliche Ausgangspunkt für die wirklich spannende Phase: die statistische Auswertung Ihrer Umfrage.
Statistische Verfahren: Wenn aus Zahlen Antworten werden
Jetzt, wo der Datensatz sauber und aufbereitet ist, beginnt der spannendste Teil: die eigentliche statistische Analyse. Hier erwecken wir die rohen Daten zum Leben und formen sie zu greifbaren Erkenntnissen. Denken Sie dabei an die Arbeit eines Detektivs: Zuerst beschreiben wir den "Tatort" mit der deskriptiven Statistik, um ein Gefühl für die Lage zu bekommen. Danach gehen wir mit der Inferenzstatistik in die Tiefe, um aus den Spuren allgemeingültige Schlüsse zu ziehen.
Der ganze Prozess fühlt sich oft an wie das Zusammensetzen eines Puzzles. Jede Kennzahl und jeder Test ist ein weiteres Teil, das uns dem Gesamtbild ein Stück näherbringt. Es geht eben nicht nur darum, irgendwelche Zahlen zu produzieren, sondern darum, die Geschichte zu erzählen, die in den Daten verborgen liegt. Gerade bei der Übersetzung von komplexen Umfragedaten in eine verständliche Analyse können Ansätze zur Datenanalyse mit KI eine enorme Hilfe sein.
Deskriptive Statistik: Das erste Kennenlernen mit Ihren Daten
Die deskriptive Statistik ist Ihr erster und zugleich wichtigster Schritt. Sie hilft Ihnen, Ihre Stichprobe zu verstehen und grundlegende Muster aufzudecken. Ohne diese Basis sind alle weiteren, komplexeren Analysen praktisch ein Blindflug.
Stellen Sie sich vor, Sie haben gerade eine Umfrage zur Mitarbeiterzufriedenheit abgeschlossen. Die deskriptive Analyse liefert Ihnen sofort Antworten auf die ersten drängenden Fragen:
- Häufigkeiten: Wie viele Mitarbeitende kommen aus welcher Abteilung? Und wie viele haben eigentlich am letzten Bonusprogramm teilgenommen?
- Mittelwerte: Wie zufrieden sind die Leute im Schnitt auf einer Skala von 1 bis 10? Wie viele Jahre arbeiten sie durchschnittlich schon im Unternehmen?
- Streuung: Gehen die Meinungen zur Zufriedenheit stark auseinander oder sind sich alle ziemlich einig? Eine hohe Standardabweichung wäre hier ein klares Warnsignal.
Diese Kennzahlen zeichnen ein erstes, aber klares Bild Ihrer Stichprobe. Sie sind das Fundament für jede spätere Interpretation und helfen Ihnen, die Ergebnisse richtig einzuordnen.
Die besondere Herausforderung von Likert-Skalen
In fast jeder Umfrage stoßen wir auf sie: Likert-Skalen (z. B. von „stimme voll und ganz zu“ bis „stimme überhaupt nicht zu“). Hier ist ein wenig Fingerspitzengefühl gefragt. Streng genommen sind das ordinalskalierte Daten, was bedeutet, dass der Abstand zwischen „stimme eher zu“ und „stimme voll und ganz zu“ nicht unbedingt derselbe ist wie zwischen zwei anderen Punkten.
In der Praxis hat es sich aber durchgesetzt, sie oft wie intervallskalierte Daten zu behandeln, um Mittelwerte und Standardabweichungen berechnen zu können. Das ist ein gängiger und meist vertretbarer Kompromiss, dessen man sich aber bewusst sein sollte. Eine durchschnittliche Zustimmung von 3,8 ist ein nützlicher Wert, aber er bedeutet nicht, dass jemand „fast voll und ganz zugestimmt“ hat. Es ist ein abstrakter Wert, der die zentrale Tendenz der gesamten Gruppe beschreibt. Mehr zur Wahl des passenden Forschungsansatzes finden Sie übrigens in unserem Artikel, der den Unterschied zwischen qualitativer und quantitativer Forschung beleuchtet.
Die deskriptive Analyse ist keine reine Formsache. Sie ist die erste Diagnose Ihrer Daten. Hohe Standardabweichungen können beispielsweise darauf hindeuten, dass es stark polarisierende Meinungen gibt, die es sich lohnt, in einem nächsten Schritt genauer zu untersuchen.
Von der Stichprobe auf die große Masse schließen
Nachdem Sie Ihre Stichprobe genau kennen, wollen Sie natürlich mehr. Sie möchten Aussagen über eine viel größere Gruppe treffen – die sogenannte Grundgesamtheit. Genau hier kommt die Inferenzstatistik ins Spiel. Mit ihr können Sie auf Basis Ihrer Stichprobe Hypothesen testen und Rückschlüsse ziehen, die weit über die direkt befragten Personen hinausgehen.
Ein Schlüsselbegriff dabei ist die statistische Signifikanz. Sie hilft Ihnen zu entscheiden, ob ein Unterschied, den Sie gefunden haben (z. B. zwischen zwei Abteilungen), wirklich „echt“ ist oder ob er vielleicht nur durch Zufall in genau dieser Stichprobe entstanden sein könnte.
Die Auswertung von Umfragen wie dem ARD-DeutschlandTREND zeigt, wie dynamisch die Bewertung der Bundesregierung in Deutschland verläuft. Im Juni 2025, nur Wochen nach dem Regierungsstart, äußerten sich lediglich 40 Prozent der Befragten positiv. Diese monatlichen Erhebungen von Infratest dimap, basierend auf repräsentativen Stichproben, demonstrieren, wie Umfrageauswertungen politische Stimmungen präzise erfassen, wobei die Genauigkeit bei durchschnittlich unter 2 Prozent Abweichung zu Wahlergebnissen liegt. Lesen Sie mehr über diese politischen Stimmungstrends auf infratest-dimap.de.
Signifikanztests in der Praxis: So geht's
Schauen wir uns ein konkretes Szenario an: Ein Unternehmen will wissen, ob Kunden, die den teuren Premium-Support nutzen (Gruppe A), wirklich zufriedener sind als die mit dem Standard-Support (Gruppe B). Die Zufriedenheit wurde auf einer Skala von 1-10 erfasst.
- Hypothese formulieren: Die Nullhypothese (H0) lautet: Es gibt keinen Unterschied in der mittleren Zufriedenheit. Die Alternativhypothese (H1) ist das, was wir vermuten: Gruppe A ist zufriedener.
- Den richtigen Test wählen: Wir vergleichen die Mittelwerte zweier voneinander unabhängiger Gruppen. Der t-Test für unabhängige Stichproben ist hier genau das richtige Werkzeug. Würden wir stattdessen untersuchen, ob es einen Zusammenhang zwischen Abteilung und der Teilnahme am Bonusprogramm gibt (also zwei kategoriale Merkmale), wäre der Chi-Quadrat-Test die bessere Wahl.
- Das Ergebnis deuten: Ihre Statistiksoftware (wie SPSS oder R) spuckt am Ende einen p-Wert aus. Ein p-Wert von unter 0,05 (das ist die gängige Grenze) sagt uns: Die Wahrscheinlichkeit, dass wir so einen großen Unterschied nur durch Zufall finden, obwohl in Wahrheit gar keiner existiert, liegt bei unter 5 %. In diesem Fall würden wir die Nullhypothese verwerfen und hätten einen statistischen Beleg dafür, dass der Premium-Support tatsächlich zu höherer Kundenzufriedenheit führt.
Die korrekte Anwendung dieser Tests ist absolut entscheidend. Sie verleiht Ihrer Analyse die nötige Tiefe und ermöglicht es Ihnen, über reine Beschreibungen hinauszugehen und wirklich fundierte, datengestützte Entscheidungen zu treffen.
Ergebnisse wirkungsvoll visualisieren und interpretieren
Statistische Kennzahlen und p-Werte sind zwar das Fundament Ihrer Analyse, aber nackte Zahlen allein sind selten fesselnd. Um Ihre Ergebnisse wirklich zum Leben zu erwecken und Ihr Publikum zu überzeugen, müssen Sie mit Ihren Daten eine Geschichte erzählen. Und der beste Weg dafür ist die Visualisierung. Eine klug gewählte Grafik macht komplexe Zusammenhänge sofort begreifbar, während seitenlange Tabellen oft nur für müde Augen sorgen.
Doch ein schönes Diagramm ist nur die halbe Miete. Der entscheidende Schritt, der eine reine Datenauflistung in eine wertvolle Auswertung von Umfragen verwandelt, ist die tiefgehende Interpretation. Hier geht es darum, die visuellen und statistischen Befunde in bedeutungsvolle Schlussfolgerungen zu übersetzen. Sie verbinden die Punkte, geben den Zahlen einen Kontext und machen klar, warum sie relevant sind.
Genau dieser Prozess legt die Botschaft hinter den Daten frei und macht sie greifbar – egal, ob für Ihren Professor, das Management oder die breite Öffentlichkeit.
Das richtige Diagramm für Ihre Geschichte wählen
Nicht jede Grafik passt zu jeder Art von Daten. Die falsche Wahl kann Ihre Kernaussage sogar verzerren oder im Keim ersticken. Der Trick ist, sich vorab eine simple Frage zu stellen: „Welche eine Botschaft will ich mit dieser Visualisierung vermitteln?“
Hier sind die gängigsten Diagrammtypen und wann sie glänzen:
- Balkendiagramme: Perfekt für den Vergleich von Kategorien. Wollen Sie die Beliebtheit verschiedener Produktfeatures oder die Zufriedenheit in unterschiedlichen Abteilungen zeigen? Dann ist das Balkendiagramm Ihr Freund. Seine Stärke liegt im direkten, unmissverständlichen Vergleich.
- Kreis- und Ringdiagramme: Setzen Sie diese sparsam ein! Sie eignen sich ausschließlich, um Anteile an einem Ganzen darzustellen, zum Beispiel die prozentuale Verteilung von Altersgruppen. Als Faustregel gilt: Bei mehr als vier oder fünf Kategorien wird ein Kreisdiagramm schnell unübersichtlich.
- Liniendiagramme: Ihre erste Wahl, wenn es um Trends und Entwicklungen über die Zeit geht. Verfolgen Sie beispielsweise die Kundenzufriedenheit über mehrere Quartale, gibt es keine bessere Darstellungsform.
- Streudiagramme: Unverzichtbar, um die Beziehung (also die Korrelation) zwischen zwei numerischen Variablen zu beleuchten. Damit visualisieren Sie, ob es einen Zusammenhang zwischen dem Preis eines Produkts und der von Kunden wahrgenommenen Qualität gibt.
Praxistipp aus Erfahrung: Finger weg von überladenen 3D-Effekten oder einem Feuerwerk an grellen Farben. Die beste Visualisierung ist oft die schlichteste. Ihr Ziel ist Klarheit, nicht künstlerische Selbstdarstellung. Mit Tools wie Excel, SPSS oder Python erstellen Sie mit wenigen Klicks professionelle Grafiken, die Ihre Geschichte auf den Punkt bringen.
Von der Beschreibung zur tiefgehenden Interpretation
Ein gutes Diagramm beschreibt, was ist. Eine brillante Interpretation erklärt, warum es so ist und was das bedeutet. Viele machen den Fehler, bei der reinen Beschreibung stehen zu bleiben („Balken A ist höher als Balken B“). Der eigentliche Wert Ihrer Arbeit liegt aber im nächsten Schritt.
Bohren Sie tiefer und stellen Sie sich die entscheidenden Fragen:
- Was bedeutet dieses Ergebnis konkret? Welche praktische Relevanz hat dieser Befund? Wenn Abteilung A signifikant unzufriedener ist, was sind die denkbaren Konsequenzen für das Unternehmen?
- Wie fügt sich das in meine Forschungsfrage ein? Stützt oder widerlegt das Ergebnis Ihre ursprüngliche Hypothese?
- Gibt es alternative Erklärungen? Könnten andere Faktoren, die Sie vielleicht nicht untersucht haben, das Ergebnis beeinflussen? Das zu reflektieren, zeugt von kritischem Denken.
Ein faszinierendes Beispiel liefert die Körber-Stiftung mit ihrer Umfrageauswertung „Demokratie in der Krise 2025“. Dort zeigt sich eine klare Kluft zwischen persönlicher Zuversicht und gesellschaftlichem Pessimismus. Während 59 Prozent ihre eigene wirtschaftliche Lage als gut bewerteten, sahen ganze 76 Prozent die Gesamtwirtschaft in Deutschland negativ. Die Interpretation geht hier weit über die Zahlen hinaus und deckt eine Wahrnehmungslücke zwischen dem Individuellen und dem Kollektiven auf – ein tiefer Einblick in die Krisenwahrnehmung der Bevölkerung. Werfen Sie einen Blick auf diese spannenden Ergebnisse zur Krisenwahrnehmung auf koerber-stiftung.de.
Den häufigsten Denkfehler vermeiden
Der wohl größte Fallstrick bei der Interpretation ist die Verwechslung von Korrelation und Kausalität. Nur weil zwei Dinge gleichzeitig passieren (wie der Anstieg von Eisverkäufen und Sonnenbränden im Sommer), heißt das noch lange nicht, dass das eine das andere verursacht. Oft steckt ein dritter Faktor dahinter – in diesem Fall die starke Sonneneinstrahlung – der beides beeinflusst.
Seien Sie daher in Ihren Formulierungen immer präzise. Sprechen Sie von „Zusammenhängen“ oder „Assoziationen“, es sei denn, Ihr Studiendesign (etwa ein echtes Experiment) lässt tatsächlich Rückschlüsse auf Ursache und Wirkung zu. Diese wissenschaftliche Genauigkeit ist das A und O für die Glaubwürdigkeit Ihrer Arbeit. Falls Sie qualitative Daten auswerten, bei denen die Interpretation von Texten im Fokus steht, finden Sie wertvolle Anleitungen in unserem Praxisleitfaden zur qualitativen Inhaltsanalyse nach Mayring.
Wenn Sie Ihre Ergebnisse überzeugend visualisieren und anschließend sorgfältig und kritisch interpretieren, machen Sie aus trockenen Daten eine fundierte Erzählung, die zum Handeln anregt. Und genau das ist das Ziel jeder gelungenen Auswertung.
Ihre Analyse in einen überzeugenden Bericht überführen
Eine brillante statistische Analyse ist nur die halbe Miete. Ihr ganzer Wert entfaltet sich erst, wenn die Ergebnisse klar, verständlich und überzeugend auf den Punkt gebracht werden. Der Bericht ist die Bühne, auf der Ihre Daten endlich ihre Geschichte erzählen dürfen.
Ganz gleich, ob es sich um eine Abschlussarbeit oder eine entscheidende Präsentation fürs Management handelt: Der Erfolg Ihrer gesamten Auswertung von Umfragen hängt von diesem letzten, entscheidenden Schritt ab. Hier übersetzen Sie die Komplexität Ihrer Analysen in eine nachvollziehbare Erzählung und führen Ihre Leser von der Methodik über die zentralen Befunde bis hin zu handfesten Schlussfolgerungen. So werden aus abstrakten Zahlen konkrete Einsichten.
Der rote Faden Ihres Berichts
Ein guter Bericht braucht eine klare, logische Struktur. Dieser rote Faden sorgt dafür, dass Ihre Leser Ihnen mühelos folgen können und keine wichtigen Informationen untergehen.
Für quantitative Analyseberichte hat sich eine Gliederung bewährt, die sich an der klassischen wissenschaftlichen Argumentation orientiert:
- Einleitung: Worum geht es eigentlich? Hier stellen Sie die Forschungsfrage vor und erklären kurz, warum das Thema relevant ist.
- Methodik: Seien Sie transparent. Beschreiben Sie Ihre Stichprobe (wer wurde befragt?), das Erhebungsinstrument (welche Fragen wurden gestellt?) und die Analyseverfahren, die Sie genutzt haben.
- Ergebnisdarstellung: Jetzt kommen die Fakten auf den Tisch. Präsentieren Sie die deskriptiven und inferenzstatistischen Befunde neutral und sachlich. Tabellen und Grafiken sind hier Ihre besten Freunde.
- Diskussion: Das ist das Herzstück Ihrer Arbeit. Was bedeuten die Zahlen wirklich? Hier interpretieren Sie die Ergebnisse, ordnen sie in den Forschungskontext ein und beantworten Ihre Forschungsfrage.
- Schlussfolgerung und Ausblick: Fassen Sie die wichtigsten Erkenntnisse zusammen. Leiten Sie daraus praktische Implikationen oder Empfehlungen für zukünftige Forschung ab.
Diese Struktur schafft eine Klarheit, die für die wissenschaftliche oder geschäftliche Akzeptanz Ihrer Arbeit absolut entscheidend ist.
Statistische Kennwerte korrekt berichten
Wenn es um statistische Ergebnisse geht, ist Präzision alles. Je nach Fachgebiet gibt es ganz spezifische Standards, wie Kennwerte dargestellt werden müssen. Gerade in den Sozialwissenschaften hat sich der APA-Stil als Goldstandard etabliert.
Wie sieht das in der Praxis aus? Hier ein Beispiel für das Reporting eines t-Tests nach APA: „Ein t-Test für unabhängige Stichproben zeigte, dass die Zufriedenheit in der Premium-Support-Gruppe (M = 7,8, SD = 1,2) signifikant höher war als in der Standard-Support-Gruppe (M = 6,5, SD = 1,4), t(198) = 5,43, p < .001.“
Ein klarer Bericht liefert nicht nur Erkenntnisse, sondern auch konkrete Handlungsempfehlungen, beispielsweise wie Sie Ihre Marketingstrategien optimieren und die Conversion Rate verbessern können. Die Fähigkeit, aus Daten handfeste Vorschläge abzuleiten, macht Ihre Analyse erst wirklich wertvoll.
Diese standardisierte Schreibweise wirkt vielleicht auf den ersten Blick etwas technisch, aber sie hat einen unschätzbaren Vorteil: Sie macht Ihre Ergebnisse für andere Forscher exakt nachvollziehbar und vergleichbar. Sie kommunizieren damit nicht nur das Ergebnis, sondern liefern auch die statistische Begründung gleich mit.
Die Diskussion: Mehr als nur Zahlen wiederholen
In der Diskussion geht es um viel mehr als eine reine Wiederholung der Fakten. Hier zeigen Sie, dass Sie die Materie wirklich durchdrungen haben. Sie interpretieren, was die Befunde im Kontext Ihrer Forschungsfrage bedeuten und warum sie wichtig sind.
Ein gutes Beispiel für die Interpretation von Umfragedaten ist die Statista-Auswertung zur Bundestagswahl 2025, die präzise Stimmenverteilungen zeigt. Die CDU/CSU erreichte 28,6 Prozent, gefolgt von der AfD mit 20,8 Prozent. Richtig spannend wird es aber erst bei der Interpretation der demografischen Unterschiede: Bei den 18- bis 24-Jährigen lag Die Linke mit 25 Prozent knapp vor der AfD (21 Prozent), während bei den über 70-Jährigen satte 50 Prozent für die Union stimmten. Solche Daten sind eine ideale Grundlage, um Korrelationen zwischen Umfrageergebnissen und demografischen Faktoren zu diskutieren. Mehr Einblicke finden Sie in der detaillierten Sonntagsfrage zur Bundestagswahl auf statista.com.
Ordnen Sie Ihre Ergebnisse in den bisherigen Forschungsstand ein. Bestätigen oder widerlegen sie frühere Studien? Welche neuen Perspektiven eröffnen Ihre Befunde? Reflektieren Sie auch selbstkritisch die Limitationen Ihrer Studie – das zeugt von wissenschaftlicher Redlichkeit und macht Ihre Arbeit nur noch glaubwürdiger.
Den Schreibprozess mit modernen Werkzeugen unterstützen
Das Schreiben selbst, vor allem das Management von Quellen und Zitationen, kann zu einem echten Zeitfresser werden. Zum Glück können moderne Tools hier eine gewaltige Erleichterung sein.
Plattformen wie KalemiFlow sind darauf ausgelegt, den Recherche- und Schreibprozess zu beschleunigen. Mit schnellem Zugriff auf eine riesige Datenbank wissenschaftlicher Artikel finden Sie mühelos relevante Literatur, um Ihre Ergebnisse in den Forschungskontext einzuordnen. Funktionen wie die interaktive PDF-Analyse oder die automatisierte Erstellung von Zitationen sparen wertvolle Stunden.
Diese Zeit können Sie dann genau dort investieren, wo es am wichtigsten ist: in die inhaltliche Tiefe Ihrer Argumentation und die sorgfältige Interpretation Ihrer Daten. Denn am Ende ist es das, was einen Bericht wirklich überzeugend macht: eine klare, logische und gut begründete Geschichte, die auf einem soliden Fundament aus Daten steht.
Häufig gestellte Fragen zur Umfrageauswertung
Wer sich mit der Auswertung von Umfragen beschäftigt, stößt früher oder später immer auf dieselben Fragen. Das ist ganz normal. Hier habe ich die häufigsten Stolpersteine aus der Praxis zusammengetragen und gebe Ihnen klare, verständliche Antworten an die Hand. Damit gehen Sie Ihr nächstes Projekt garantiert souveräner an.
Wie groß muss meine Stichprobe sein?
Die Gretchenfrage schlechthin! Die ehrliche Antwort eines jeden Statistikers lautet: „Es kommt darauf an.“ Aber worauf genau? Im Grunde sind es drei Hebel, an denen Sie drehen müssen.
Zuerst geht es um die Grundgesamtheit – also die gesamte Gruppe, über die Sie am Ende etwas aussagen wollen. Dann kommt das Konfidenzniveau ins Spiel. In der Wissenschaft und Marktforschung hat sich hier ein Standard von 95 % etabliert, was bedeutet, dass Ihre Ergebnisse mit hoher Wahrscheinlichkeit kein Zufall sind. Zuletzt legen Sie die Fehlertoleranz fest, die meistens bei 3 % bis 5 % liegt.
Für sehr große Gruppen, wie etwa die Bevölkerung Deutschlands, reichen oft schon 1.000 bis 2.000 zufällig ausgewählte Personen für ein aussagekräftiges Bild. Viel wichtiger als die reine Anzahl ist aber die Art der Auswahl: Sie muss zufällig sein! Nur so stellen Sie sicher, dass Ihre kleine Gruppe die große Grundgesamtheit auch wirklich repräsentiert. Machen Sie es sich einfach und nutzen Sie einen der vielen kostenlosen Online-Rechner, um die genaue Zahl für Ihr Projekt zu ermitteln.
Was ist der Unterschied zwischen Korrelation und Kausalität?
Das ist einer der wichtigsten Punkte, der selbst in professionellen Berichten oft falsch dargestellt wird. Eine Korrelation ist erstmal nichts weiter als ein statistischer Zusammenhang. Wenn Variable A steigt, steigt (oder fällt) Variable B ebenfalls. Mehr nicht.
Eine Kausalität geht viel weiter. Sie behauptet, dass A die Ursache für die Veränderung in B ist. Das lässt sich aus einer Korrelation niemals direkt ableiten. Das Paradebeispiel: Im Sommer steigen die Eisverkäufe und gleichzeitig die Zahl der Sonnenbrände. Beide Phänomene korrelieren stark, aber niemand würde behaupten, dass Eiscreme Sonnenbrand verursacht. Der wahre Grund ist ein dritter Faktor: die starke Sonneneinstrahlung.
Bei der reinen Auswertung einer Umfrage können Sie fast immer nur Zusammenhänge, also Korrelationen, aufdecken. Echte Ursache-Wirkungs-Beziehungen nachzuweisen, gelingt in der Regel nur mit experimentellen Designs, bei denen Sie eine Variable gezielt verändern und die Folgen messen.
Bleiben Sie in Ihren Berichten also immer präzise. Sprechen Sie von „Zusammenhängen“ oder „Assoziationen“, um keine falschen Schlussfolgerungen zu provozieren.
Welche Software eignet sich am besten für die Analyse?
Die perfekte Software für alle gibt es nicht. Die Wahl des richtigen Werkzeugs hängt immer von Ihren Zielen, Ihrem Budget und Ihrem technischen Know-how ab.
Hier ist eine grobe Orientierung:
- Excel: Für den schnellen Einstieg ist Excel oft goldrichtig. Wenn Sie einfache deskriptive Statistiken wie Häufigkeiten oder Mittelwerte brauchen und ein paar simple Diagramme erstellen wollen, kommen Sie damit schon sehr weit.
- SPSS: Sobald es anspruchsvoller wird und Sie t-Tests, Varianzanalysen oder Regressionen durchführen müssen, ist SPSS eine hervorragende Wahl. Die menügeführte Oberfläche macht es deutlich zugänglicher als reine Programmiersprachen. Der Haken: Es ist kostenpflichtig, aber viele Hochschulen bieten ihren Studierenden Lizenzen an.
- R und Python: Das sind die Kraftpakete unter den Analyse-Tools. R und Python sind extrem mächtig, flexibel und dazu noch kostenlos. Der Preis dafür ist eine steilere Lernkurve, da Sie hier programmieren müssen. Für wirklich tiefgehende, maßgeschneiderte Analysen sind sie aber unschlagbar.
Gerade für Studierende ist SPSS oft der ideale Mittelweg, der einen riesigen Funktionsumfang mit einer noch gut handhabbaren Bedienung vereint.
Möchten Sie Ihren Recherche- und Schreibprozess für wissenschaftliche Arbeiten optimieren? KalemiFlow unterstützt Sie mit intelligentem Zugriff auf über 660 Millionen wissenschaftliche Dokumente, präziser Zitationserstellung und kontextbezogenen Textvorschlägen. Vereinfachen Sie Ihre Literaturrecherche und konzentrieren Sie sich voll auf den Inhalt Ihrer Arbeit. Erfahren Sie mehr auf https://kalemiflow.de.